To test a distributed system may often tough work. We need to make sure all nodes are running properly before running the test. We need to make sure all packages and source code are deployed properly in a distributed manner. We always do stuff like that everytime we change the code. There are many distributed execution framework such as Hadoop nowadays but it’s still not as easy as we do to run a simple Rails application.
Docker should be a framework to change the situation. We do not need to launch physical instance or EC2 if the isolated environment is available by using Docker. Even running a distributed system in a local machine with one command is achievable. So that’s why I tried to run the major two distributed system with docker-compose.
| Name | Distributed System |
|---|---|
| docker-hadoop-cluster | Hadoop,YARN,HDFS |
| docker-presto-cluster | Presto |
Both frameworks have a similar structure. There are base image and master, worker images. Hadoop and Presto use the same binary to run both
master and worker processes and also there is some shared configuration set between these two processes. So I include these basic components in the base image called hadoop-base or presto-base. Here is the hierarchy of the images.
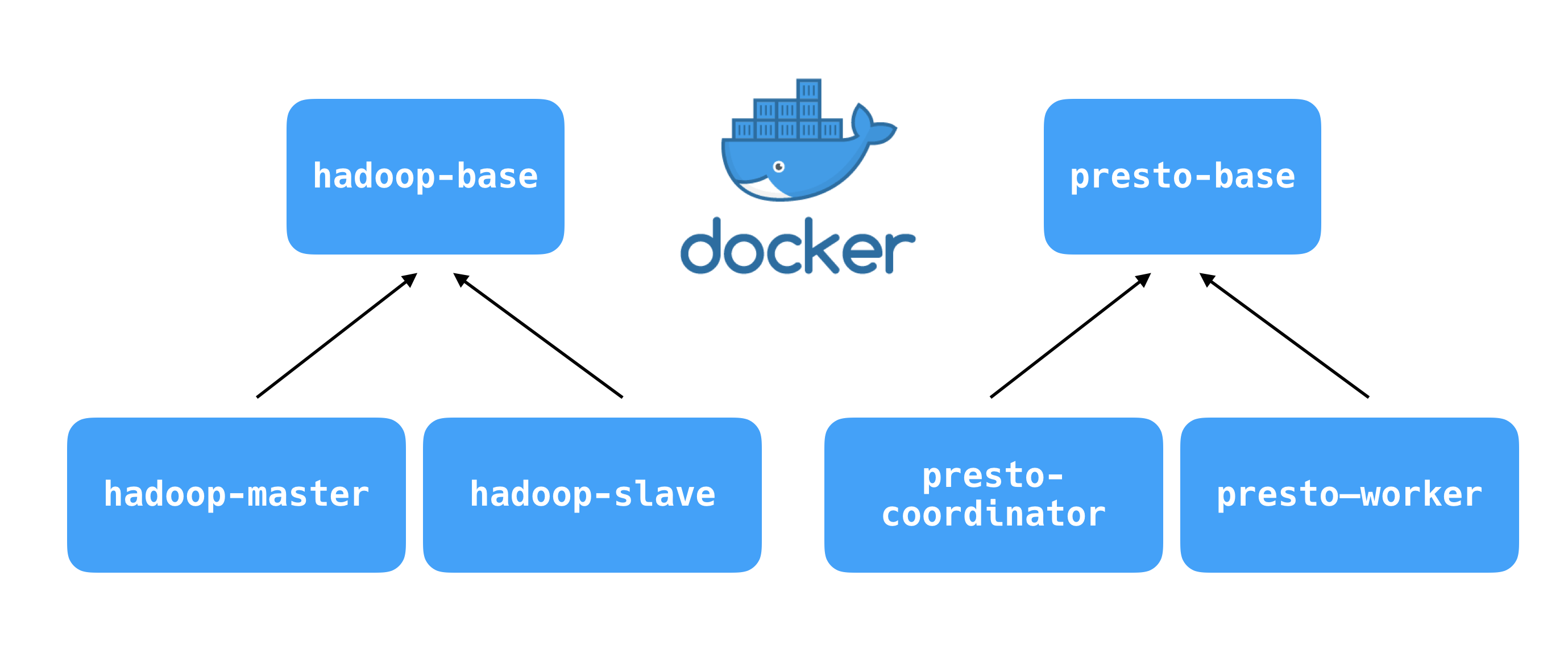
hadoop-master and presto-coordinator are the image for the master process. hadoop-slave and presto-worker are the images for the worker process. The difference between master and worker image are some part of the configuration and port number exposed to the host side. We can share the most code and configuration by sharing *-base image.
The good thing about docker-hadoop-cluster and docker-presto-cluster is that we can use our own Hadoop or Presto package. In the base image, the prebuild binary is included.
# hadoop-base
ADD hadoop-${HADOOP_VERSION}.tar.gz /usr/local/
# presto-base
ADD presto-server-${PRESTO_VERSION}.tar.gz /usr/local
That indicates we can test OUR OWN Hadoop or Presto modified by ourselves. It can make it easy to develop Hadoop or Presto itself. To be honest, the original reason I created them was to accelerate the speed of development of Hadoop and Presto. I wanted to contribute these frameworks but testing the patch I created was always difficult and time-consuming. By using this docker images, I could run Hadoop or Presto cluster with several worker nodes even in my local machine with one command.
docker-compose coordinates multiple containers. That is the tool enabling us to launch a cluster with multiple workers with one command. docker-compose.yml shows how to coordinate multiple containers created by docker-compose. Here is the example to launch a Presto cluster with 3 worker containers.
version: '3'
services:
coordinator:
build:
context: ./presto-coordinator
args:
node_id: coordinator
ports:
- "8080:8080"
container_name: "coordinator"
worker0:
build:
context: ./presto-worker
args:
node_id: worker0
container_name: "worker0"
ports:
- "8081:8081"
worker1:
build:
context: ./presto-worker
args:
node_id: worker1
container_name: "worker1"
ports:
- "8082:8081"
worker2:
build:
context: ./presto-worker
args:
node_id: worker2
container_name: "worker2"
ports:
- "8083:8081"
Once you have this docker-compose.yml, the following command will launch the cluster.
$ docker-compose up -d
You can enter the master container by running this.
$ docker-compose exec coordinator bash
You can run a query, debug and look into the log files. The whole source code and detail instruction is stored in the GitHub repositories.
I hope it will accelerate your distributed system development.
Thanks!