As described here, I have started OMSCS program in the last year. I’ve already taken 2 courses in the last semester which were about the operating system and machine learning.
The reason why I choose these courses was that I’m familiar with these topics. I studied the detail of operating system programming and learned machine learning mathematics during my first company. I thought it might be the good start of OMSCS because I thought I need to get used to the process and know what OMSCS looks like.
But in this semester, I choose a program I’m not familiar with, Computer Network. CS6250 is a class exploring the research topics in computer networking, especially the IP layer and above. Since I’m not a network engineer, I’m not so familiar with these topics. It may be a good chance to learn them. Knowledge of computer networking should be useful even in the age when cloud computing is so natural. To be honest, we can often create software or web services without knowing the detail of the underlying networking structure. But in order to purely improve my knowledge and skill by leaning unfamiliar things, I decided to take the course in Spring 2019.
What is Spanning Tree Protocol?
Spanning Tree Protocol (STP) is the first notion I did not know initially. In this article, I’m going to describe what the spanning tree protocol is based on what I learn so far.
Spanning tree protocol is a distributed protocol to construct a spanning tree structure in the given network topology. This algorithm is expected to detect the minimum network topology excluding any internal loop. Let’s say we have the following network including loop structure inside.
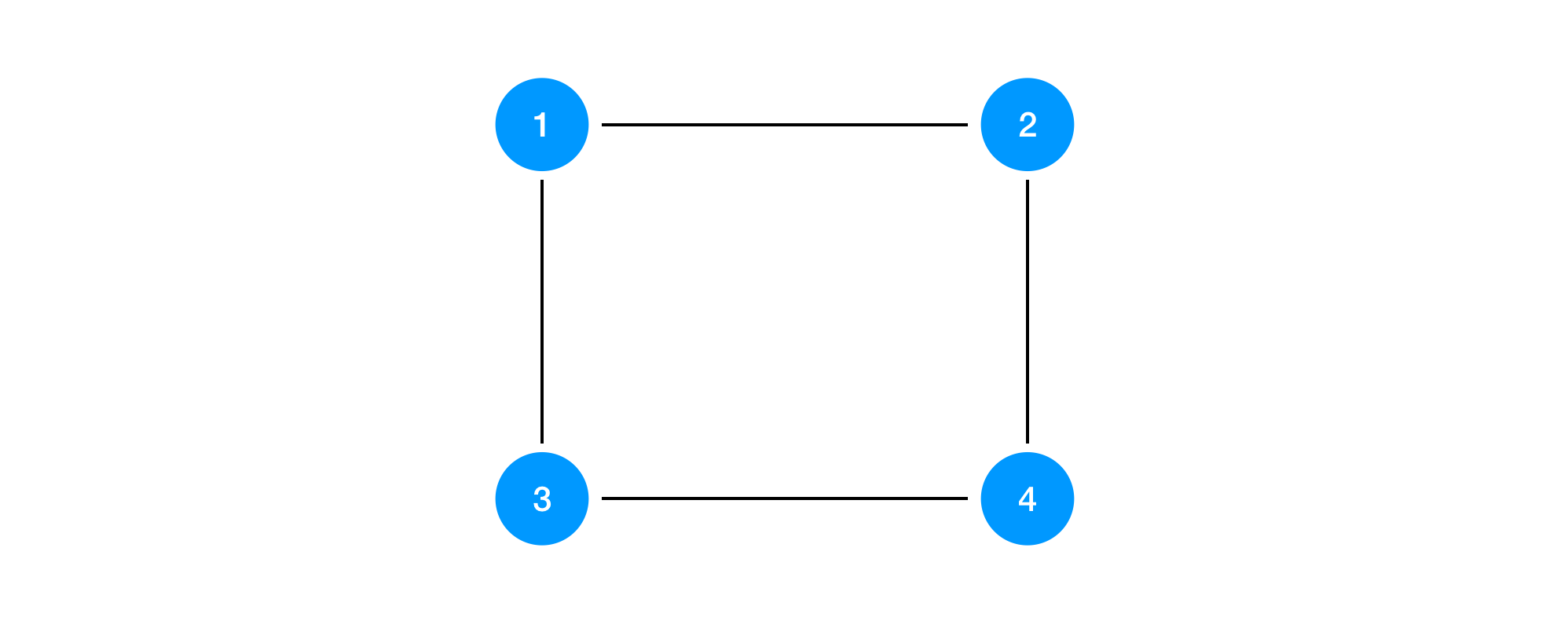
Each blue node represents a switch that basically broadcast all incoming packets. What happens if a node broadcast a package to other nodes? The network has a loop so that incoming packets are kept sent infinitely. A packet from 1 to 3 will be going to 4 and then 2. Other packet will traverse 1 -> 2 -> 4 -> 3 -> 1 -> … So a loop in a network topology connected by switches can easily cause congestion. It’s a situation famously known as a broadcast storm. It is necessary to remove the loop by excluding some edges. But how?
Spanning tree protocol detects the minimum edges required to construct the network all nodes are connected. The following one is the spanning tree in the above network. Since there is no loop, all packets sent from a node will reach the end eventually.
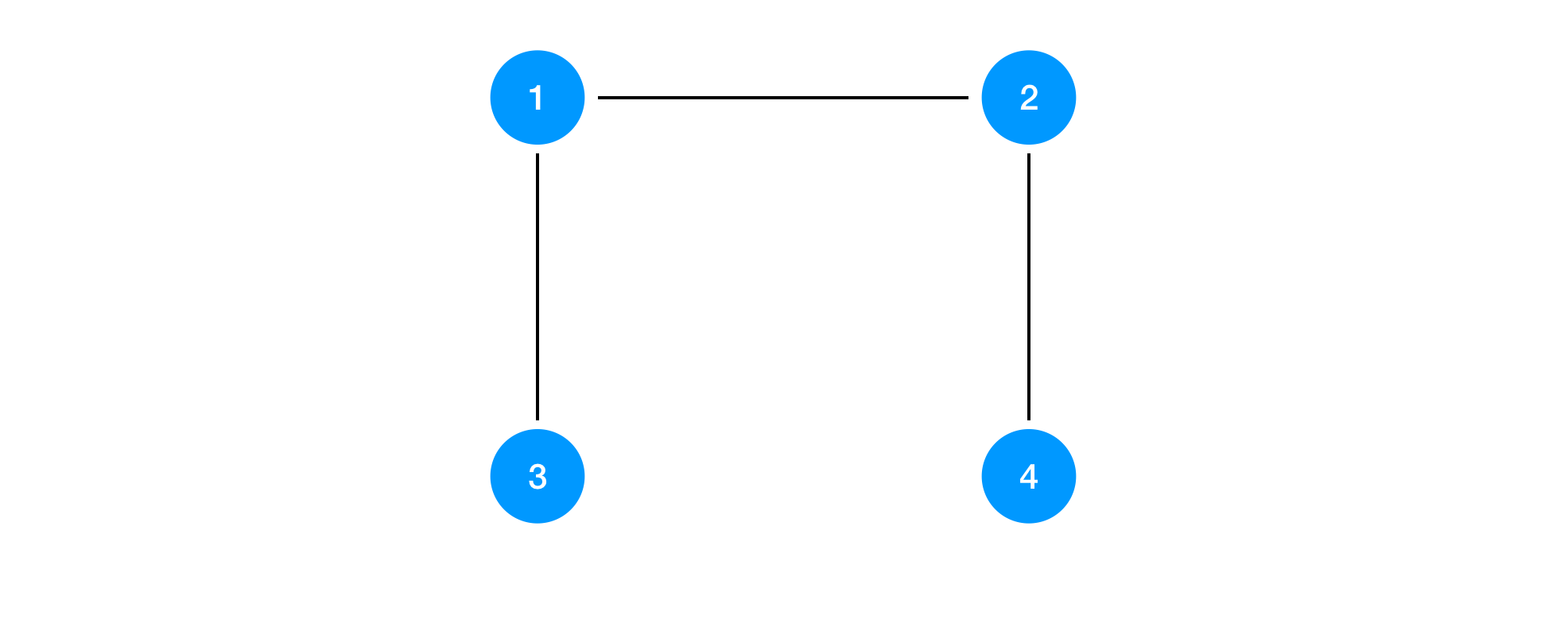
Spanning tree protocol is a distributed algorithm to find the spanning tree of given network topology. You may already know Kruskal’s and Prim’s algorithms to find the minimum spanning tree. But spanning tree protocol is a different algorithm working in a distributed manner. There is no coordination between nodes so that each node can work completely independently. Just sending specific messages to each other, a network itself find the spanning tree in the network.
How Spanning Tree Protocol Works?
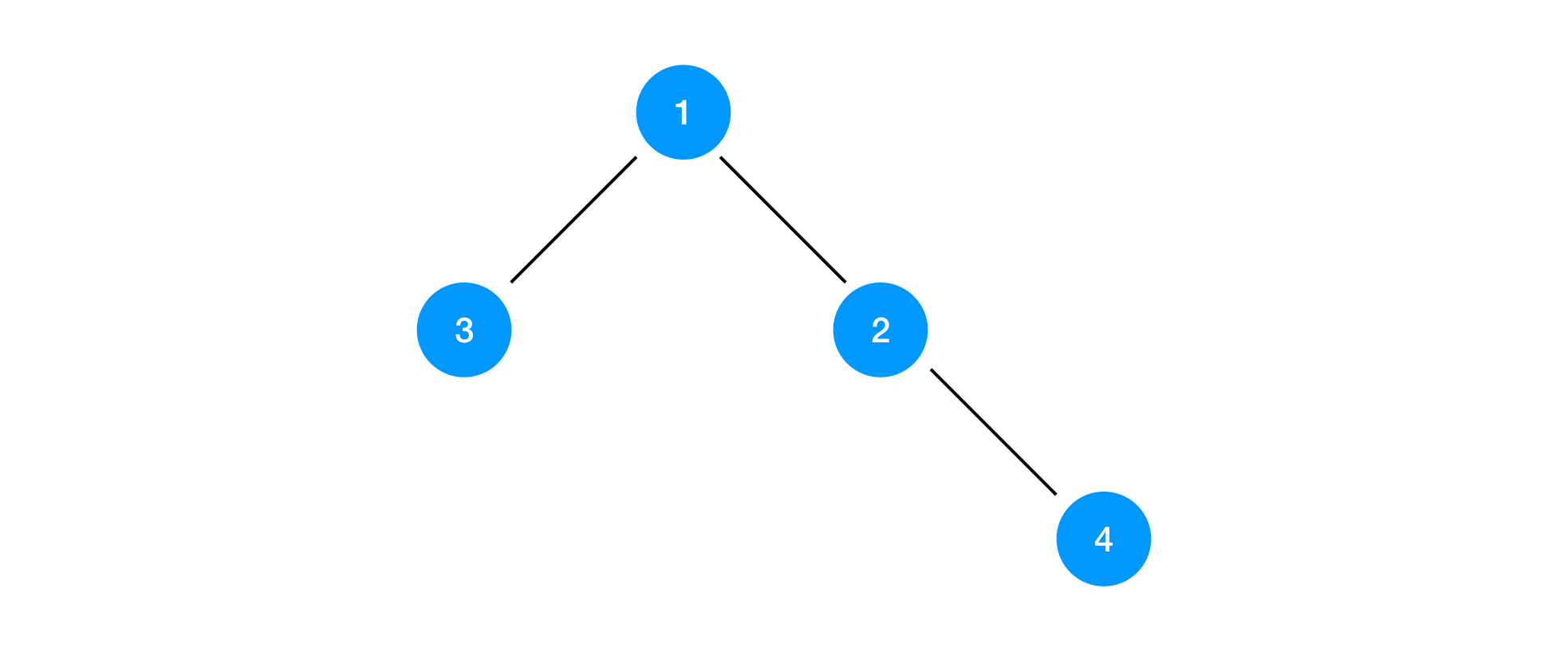
So let’s take a look into how the algorithm works. First, we are going to label all node with unique IDs. We can use distinct integers here. In the precedent case, we have labeled 4 nodes with 1, 2, 3 and 4. Basically, the spanning tree protocol is a process to find the path to the root node whose ID is the minimal one. In the aforementioned case, node 1 will be the root node.
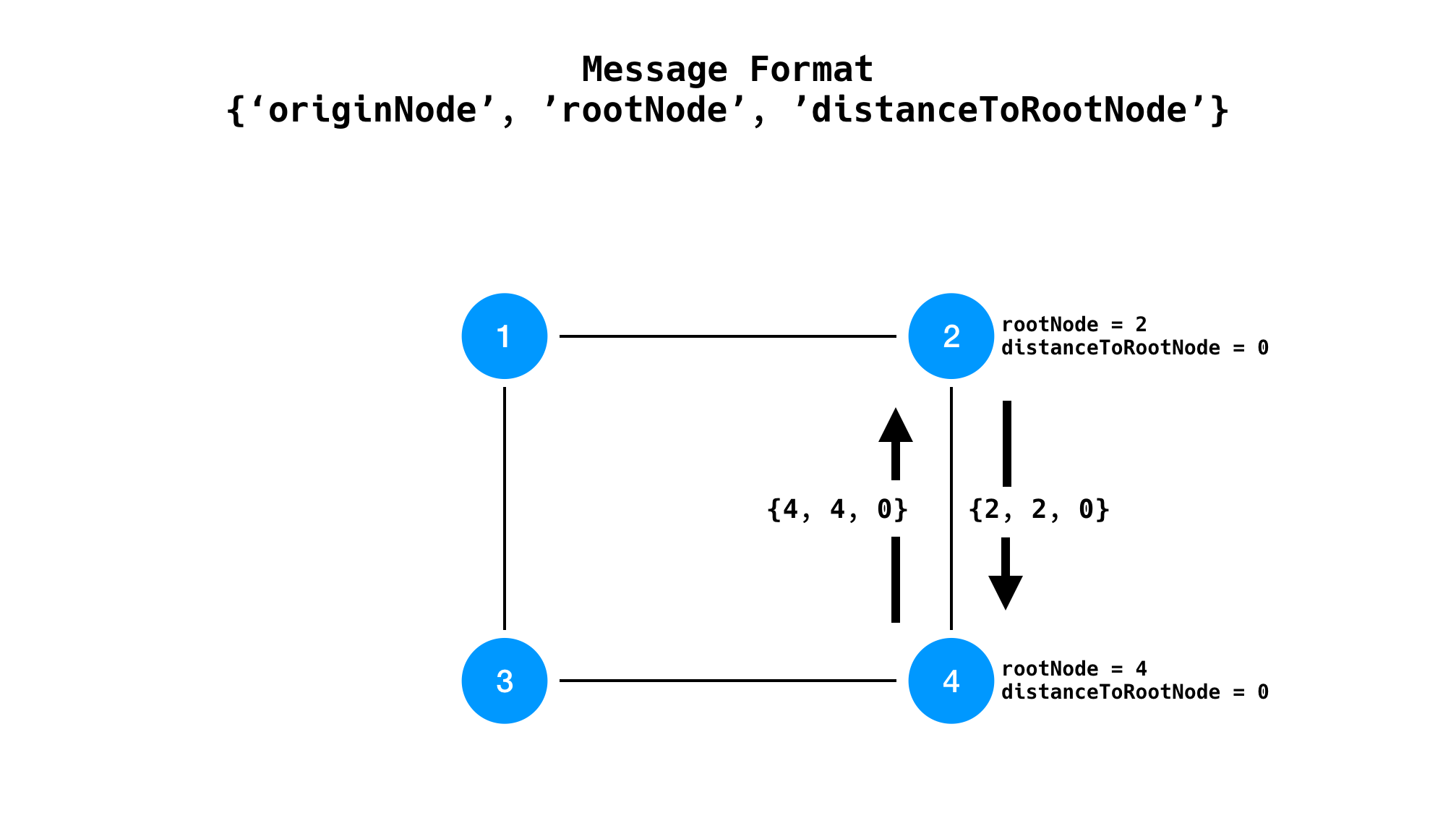
When the algorithm starts, each node sends the initial message including the following information.
| Key | Description |
|---|---|
originNode |
The node which the message is sent from. |
rootNode |
The node which the origin node assumes it the root. |
distanceToRootNode |
The distance from the origin to the node. |
Initially, we assume every node regard itself as the root node. Every node will send the messages like this.
{'originNode': Self node ID, 'rootNode'; Self node ID, 'distanceToRootNode': 0}
For example node 2 will send {'originNode': 2, 'rootNode': 2, 'distanceToRootNode': 0} to every neighbor node. One note is that each node can send a message to only neighbor nodes. The state change in the node only conveyed to the nodes next to it.
Other nodes check the message. If the origin node ID is lower than the node ID which it assumes the root, it will update the root node and corresponding the distance. In the following diagram, node 4 changes its own assumption about the root node.
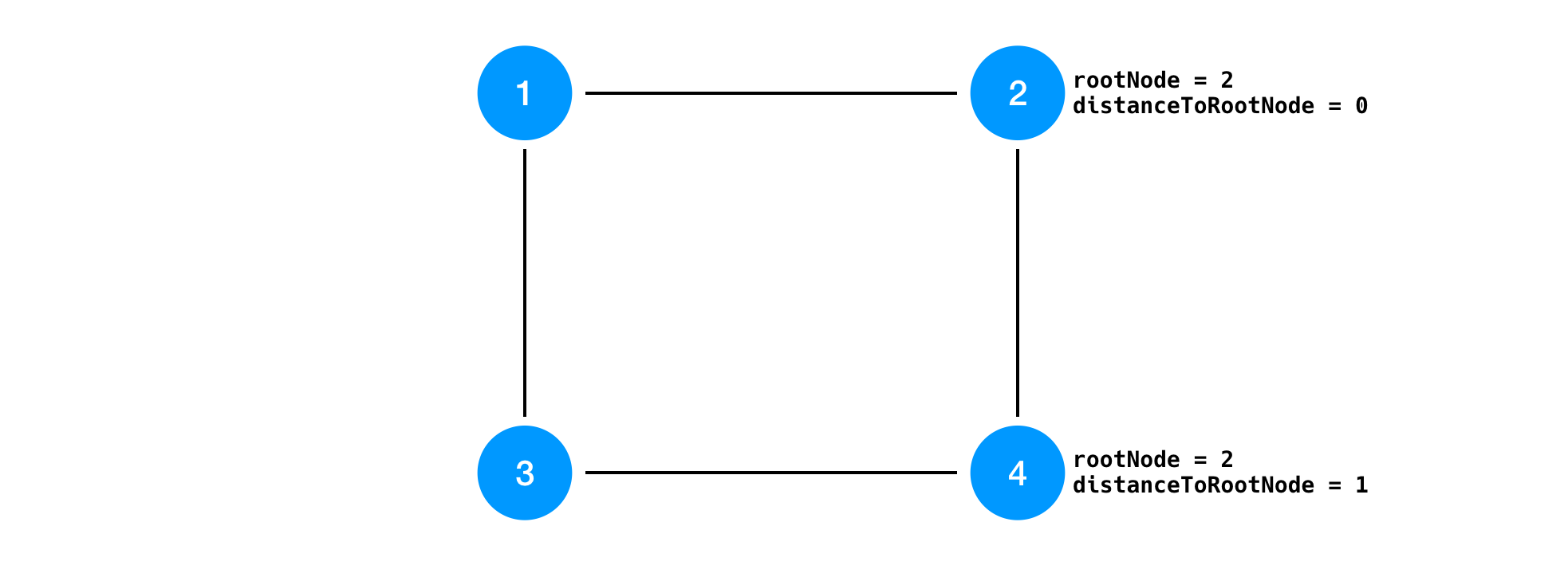
Each node only keeps the routes which lead to the root note. Node 4 receives the message from node 3 but it keeps assuming node 2 is the root because node 2 is lower than 3. So the route between node 3 and 4 will be dropped and then we will obtain the final spanning tree as shown in the beginning.
Let’s take a look into another topology.
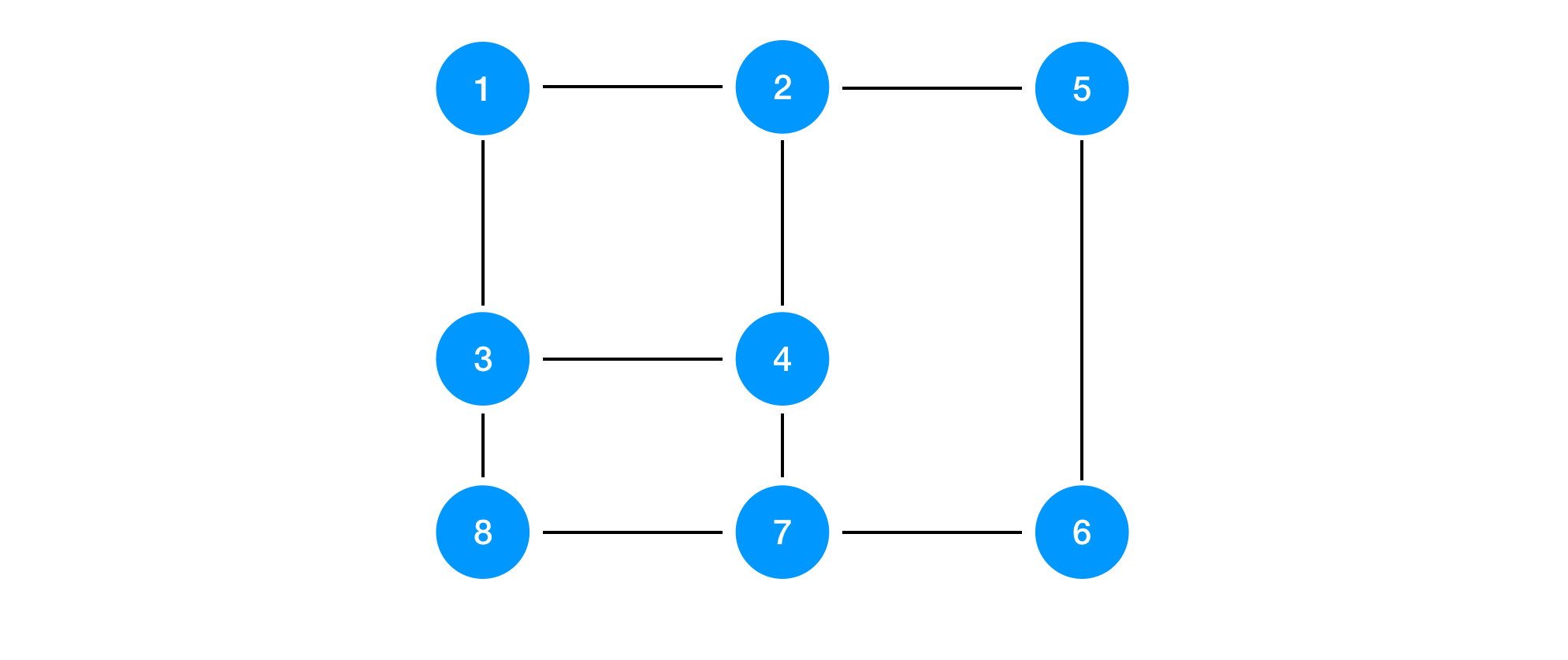
In this topology, node 1 should be the root node. Although it may take some time due to the multiple possible root node in the halfway, the following message passing will make the network converge and find the spanning tree. Node 8 and node 6 will receive multiple ways to reach to the root node. They should always choose the shortest one. So 8 will keep the route to node 3, not node 7 because it takes more steps to reach node 1.
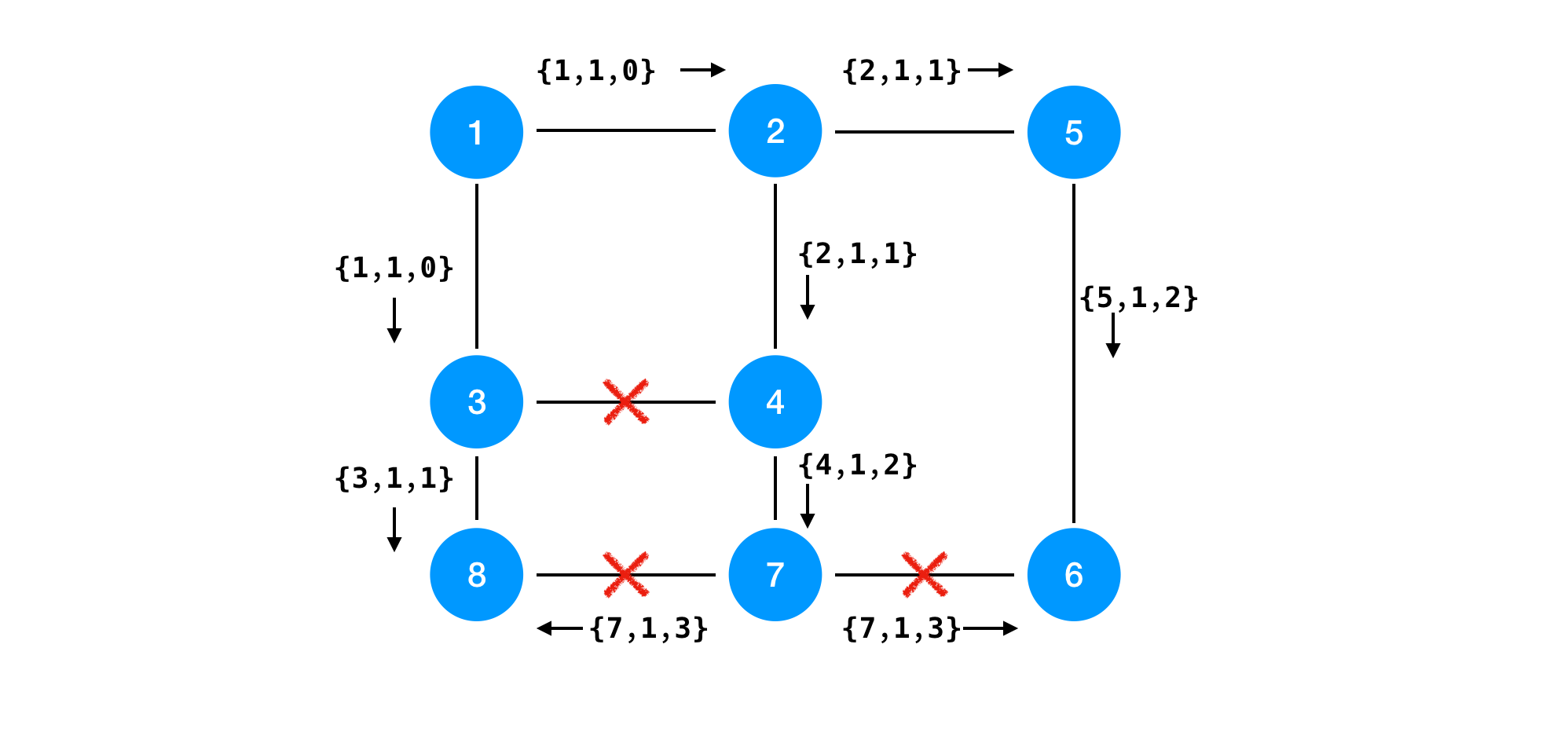
After removing the route marked red crosses, we get the spanning tree of the network topology. Of course, we have several other things to consider in reality. But grasping this kind of overview would be helpful to construct a more complicated one.
“Network Warrior”, Gary A. Donahue provides the concrete algorithm which is used in the real world. For now, I could not find the other book touching the spanning tree protocol as described here. The book will give you more insight into the computing network because it covers broader topics.
Thanks!