Machine learning is one of the hottest fields these days. No one can stop this emerging field’s progress, and no one can know the true potential of machine learning applications. The new concept or new design of the model is appearing day by day. That’s true.
But it’s also true that every machine learning (ML) application, artificial intelligence (AI), is still running the ordinary von-Neumann computer we are all familiar with. Hence, all ML applications and AI need to be compiled into the format our favorite can execute. The shadow hero of this challenge is compilers.
The intensive research in the field of a compiler for ML has been done this year. You can find vast amount of papers regarding this topic. In addition to the research, there is much software implementing the cutting-edge concept of the compiler for ML. Here is a tiny part of the whole compiler for ML.
In this article, I tried to create a minimal example to show a “Hello, World”-like a message with MLIR. (Reality, the title should have been “Hello, Tensor in MLIR”) You can find the excellent tutorial documentation in the official site of MLIR. But the toy language is a little bit larger than I expected. All I want to do was printing some data in standard output with the code generated by MLIR.
The whole code has been put in Lewuathe/mlir-hello.
With this Dialect, you can run the following program to print the elements of a tensor.
# Lower MLIR to LLVM IR and execute it
$ ./build/bin/hello-opt ./test/Hello/print.mlir | lli
1.000000 1.000000 1.000000
1.000000 1.000000 1.000000
We are going to walk through the series of articles working as practical tutorials to develop MLIR Dialect.
What is MLIR
Let’s briefly describe MLIR first. MLIR is a compiler infrastructure supporting higher-level intermediate representation than LLVM. More accurately, MLIR is a framework to extend the compiler infrastructure itself. In the past, we had a bunch of front-end languages, optimization passes, and backend hardware. They are isolated, and the code which otherwise should be reused is reinvented again and again. LLVM successfully achieves to remove the code duplication and share the knowledge among developers. But fine-grained optimization process may require a higher-level understanding of the front-end language semantics and structure.
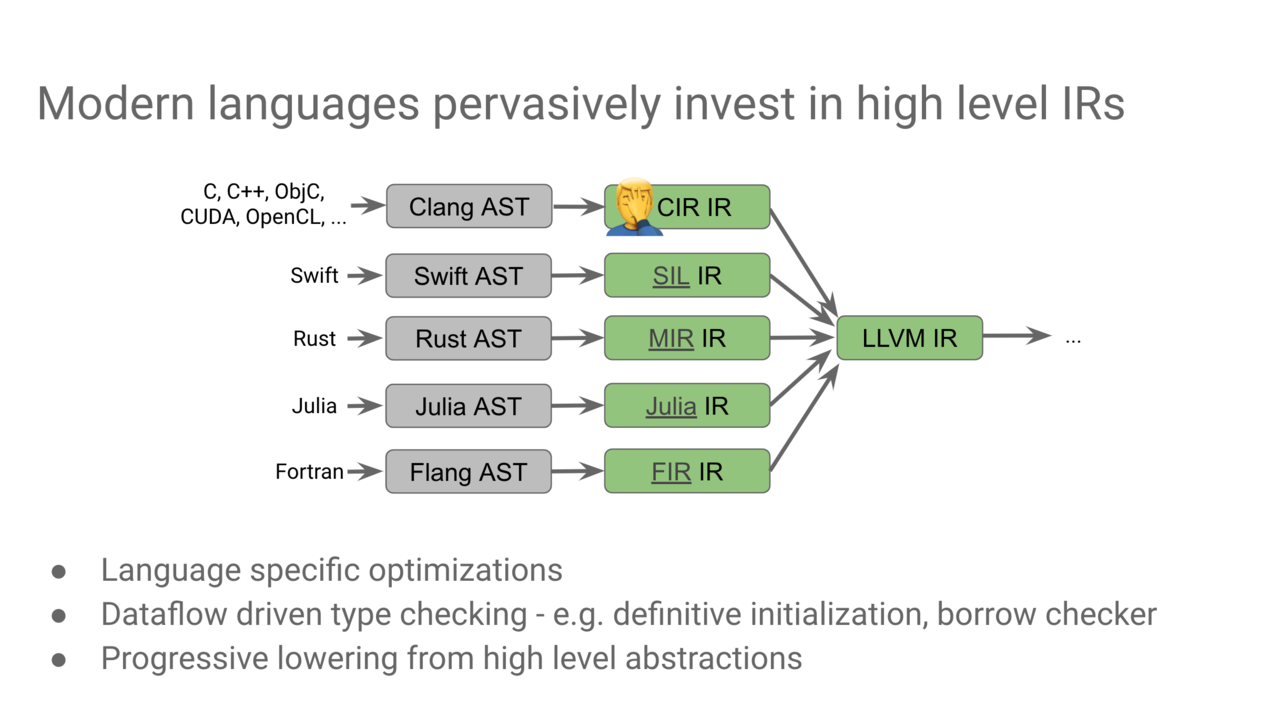
That’s why many languages develop their own IR (e.g., SIL, MIR) for the optimization and transformation along awarding the high-level language structures. The motivation of MLIR is to remove this redundant work by introducing the comprehensive framework for the high-level transformation of IR.
The ML in MLIR does not stand for Machine Learning. It’s an abbreviation of Multi-Layer Intermediate Representation whose goal is to lower the high-level language and keep the multi-layered language structures defined by Dialect to hardware code so that the MLIR framework is capable of recognizing the semantics of the higher-level language. This lowering process is the core idea of MLIR. Please see lowering part in the documentation for more.
MLIR supports plugin-architecture called Dialect. You can extend almost anything of MLIR functionality by using that. That’s so powerful that you may find yourself an inventor of a programming language! We’ll see how we implement a new dialect by looking into the Hello Dialect I have written.
Install LLVM and MLIR
At first, we need to compile the MLIR from the latest branch of the LLVM project.
git clone https://github.com/llvm/llvm-project.git
cd llvm-project
mkdir build && cd build
cmake -G Ninja ../llvm \
-DLLVM_ENABLE_PROJECTS=mlir \
-DLLVM_BUILD_EXAMPLES=ON \
-DLLVM_ENABLE_ASSERTIONS=ON \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_RTTI=ON \
-DLLVM_TARGETS_TO_BUILD="host"
cmake --build . --target check-mlir
Please make sure to use -DCMAKE_BUILD_TYPE=Release. We need to use the release version of the tools and binaries for Dialect development. You can find the official build instruction here.
Since it will take 10~20 minutes or more, let’s deep dive into the Dialect codebase next time.
Thanks!