Glow supports the heterogenous partitioning which allows us to split the input model into multiple segments according to the given device configuration.
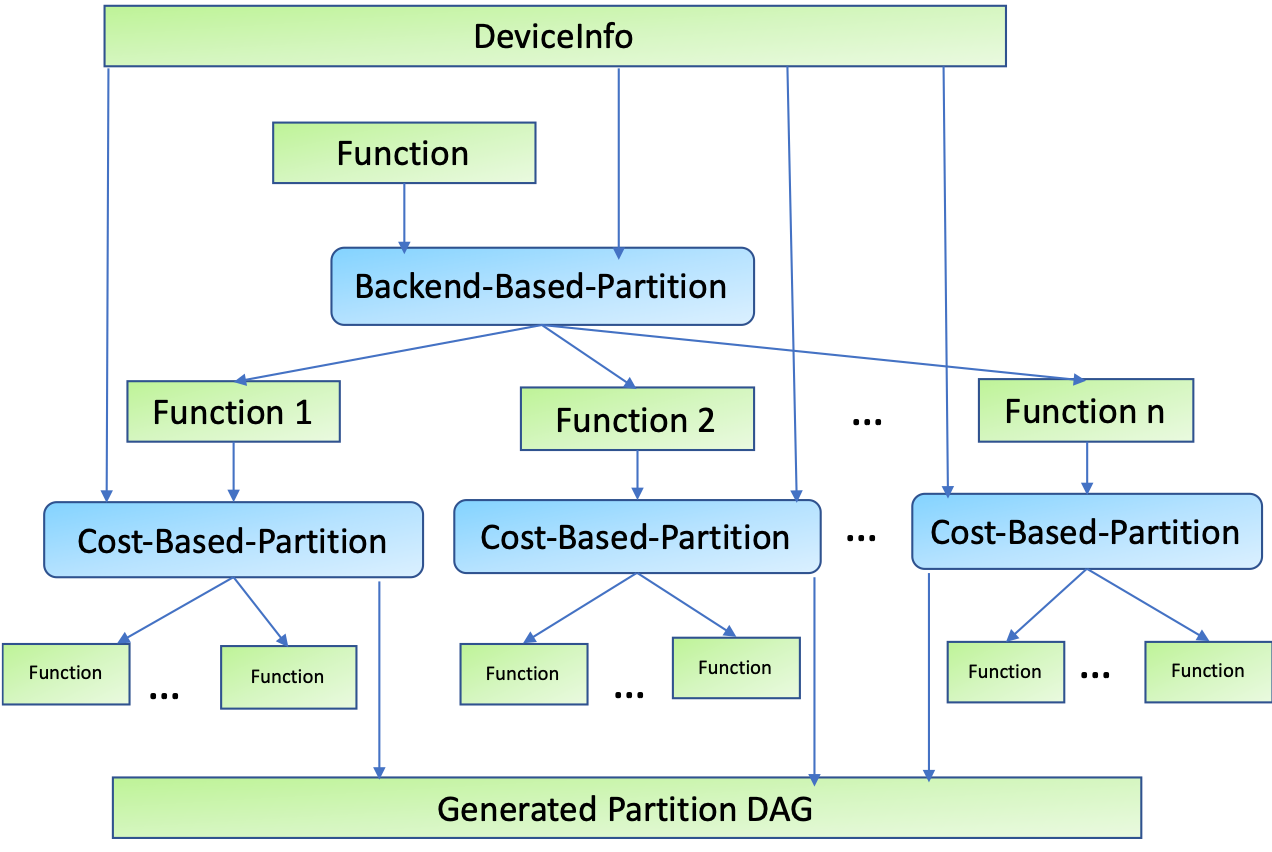
A Glow backend sometimes has unsupported operators due to the limitation of the functionality. Additionally, some backend provides more performant execution for the specific operator. Graph partitioning gives us more chance to improve the performance and reliability by making the most of the available resources for the computation.
It is necessary to write the device configuration to achieve the heterogeneous partitioning as follows.
---
- name: Device1
backendName: CPU
parameters: |
"deviceID" : "0"
- name: Device2
backendName: OpenCL
parameters: |
"nonSupportedNodes": "ResizeBilinear"
"deviceID": "1"
This file instructs Glow to be aware of two platforms to run the partition. One is CPU on the host machine; the other is GPU device providing OpenCL API. Since OpenCL backend does not support ResizeBilinear, we marked it as nonSupportedNodes so that Glow will automatically put the operator on CPU instead.
But when I tried to partition the MobileNet v3 model in ONNX, I’ve got the following message.
$ ./bin/image-classifier \
-model=../../mobilenetv2-7.onnx \
-load-device-configs=../../heterogeneousConfig-bad.yaml \
-log-partition=true \
../../glow/tests/images/imagenet/cat_285.png \
-model-input-name=input \
-onnx-define-symbol=batch_size,1
...
I0629 06:16:44.610828 23057 Partitioner.cpp:88] The number of partitions is : 1
I0629 06:16:44.610846 23057 PartitionerUtils.cpp:549] Partition 0:
Name : ../../mobilenetv2-7.onnx_part1_part1
BackendKind : CPU
context count : 1
total Memory : 14557376
input size: 602112
input count : 1
input only from peers count : 0
output size: 4000
constant size: 13951264
No partitioning looks happen, and all operators seem to be assigned to the CPU backend. That’s a bizarre situation.
After a while digging deeper into the code base, I found the cause in partitioner of Glow.
Expected<DAGListTy> Partitioner::backendBasedPartition(
FunctionToBackendNameMap &funcToBackend, Function *F,
std::vector<Backend *> &backends, CompilationContext &cctx) {
NodeToFunctionMap mapping;
llvm::DenseMap<Node *, std::string> nodeToBackendName;
// For each node find a backend that supports it.
for (auto &N : F->getNodes()) {
for (auto &backend : backends) {
// Find the first backend that supports this node. The order of backends
// is important. The check flow is :
// ...
}
// ...
}
}
The algorithm is first-come-first-served, which always prefers the backend coming first if it supports the operator. Accidentally, the CPU backend generally supports more operators than the OpenCL backend. Therefore, the configuration file having CPU first always leads to the single partition backed by CPU. To overcome the situation, we can reorder the backends listed in the configuration file.
---
- name: Device2
backendName: OpenCL
parameters: |
"nonSupportedNodes": "ResizeBilinear"
"deviceID": "1"
- name: Device1
backendName: CPU
parameters: |
"deviceID" : "0"
I’ve just switched the order of CPU and OpenCL devices.
I0629 06:31:54.274185 23240 Partitioner.cpp:88] The number of partitions is : 1
I0629 06:31:54.274202 23240 PartitionerUtils.cpp:549] Partition 0:
Name : ../../mobilenetv2-7.onnx_part1_part1
BackendKind : OpenCL
context count : 1
total Memory : 14557376
input size: 602112
input count : 1
input only from peers count : 0
output size: 4000
constant size: 13951264
I0629 06:31:54.274243 23240 PartitionerUtils.cpp:5
Now every operator is assigned to the OpenCL backend. If a model like FCN containing resize operator, we will get the following partitioning layout.
I0629 06:34:34.624155 23388 Partitioner.cpp:88] The number of partitions is : 3
I0629 06:34:34.624177 23388 PartitionerUtils.cpp:549] Partition 0:
Name : ../../fcn.onnx_part1_part1
BackendKind : OpenCL
context count : 1
total Memory : 217777448
input size: 602112
input count : 1
input only from peers count : 0
output size: 131712
constant size: 217043624
I0629 06:34:34.624246 23388 PartitionerUtils.cpp:570] LogicalDeviceIDs : 1
I0629 06:34:34.624260 23388 PartitionerUtils.cpp:549] Partition 1:
Name : ../../fcn.onnx_part2_part1
BackendKind : CPU
context count : 1
total Memory : 8561280
input size: 131712
input count : 2
input only from peers count : 0
output size: 8429568
constant size: 0
I0629 06:34:34.624302 23388 PartitionerUtils.cpp:570] LogicalDeviceIDs : 0
I0629 06:34:34.624315 23388 PartitionerUtils.cpp:549] Partition 2:
Name : ../../fcn.onnx_part3_part1
BackendKind : OpenCL
context count : 1
total Memory : 16859136
input size: 8429568
input count : 2
input only from peers count : 0
output size: 8429568
constant size: 0
One thing to note in this article is the order-sensitiveness of the device configuration in Glow. So we should put the weaker device first and the strong backend like Interpreter or CPU to increase the chance of balanced distribution of partitions.