The Internet consists of multiple router nodes which decide the destination packet should be sent. Each router on the Internet needs to send the packet to the appropriate target node decided by the given IP destination. But how each router can decide the next destined router with the given IP address?
Longest Prefix Match
Longest prefix match is an algorithm to lookup the IP prefix which will be the destination of the next hop from the router. The routing table each router stores IP prefix and the corresponding router. This algorithm is used to find the prefix matching the given IP address and returns the corresponding router node. For example, let’s consider the following case.
| IP Prefix | Router |
|---|---|
| 192.168.20.16/28 | A |
| 192.168.0.0/16 | B |
When the given IP address 192.168.20.19 is given, which entries should be picked up? According to the longest prefix match algorithm, node A will be chosen. Because it has a longer subnet mask. The bold numbers are the bits matching the IP address. You can know 192.168.20.16/28 has the longer prefix than 192.168.0.0/16 has.
| Hex Format | Binary Format |
|---|---|
| 192.168.20.191 | 11000000.10101000.00010100.10111111 |
| 192.168.20.16/28 | 11000000.10101000.00010100.00010000 |
| 192.168.0.0/16 | 11000000.10101000.00000000.00000000 |
Generally speaking, the longest prefix match algorithm tries to find the most specific IP prefix in the routing table. This is the longest prefix match algorithm But looking up the routing table naively is pretty inefficient because it does a linear search in the IP prefix list and picks up the prefix with the longest subnet mask. The more entries the routing table has, the longer it takes to lookup. How can we do this more efficient manner?
Address Lookup Using Trie
Using trie is one solution to find the longest match prefix. Trie is a data structure whose nodes have a part of the prefix. By the nature of the tree data structure, we can search the prefix efficiently by traversing the tree. Let’s take a look at the following simple example.
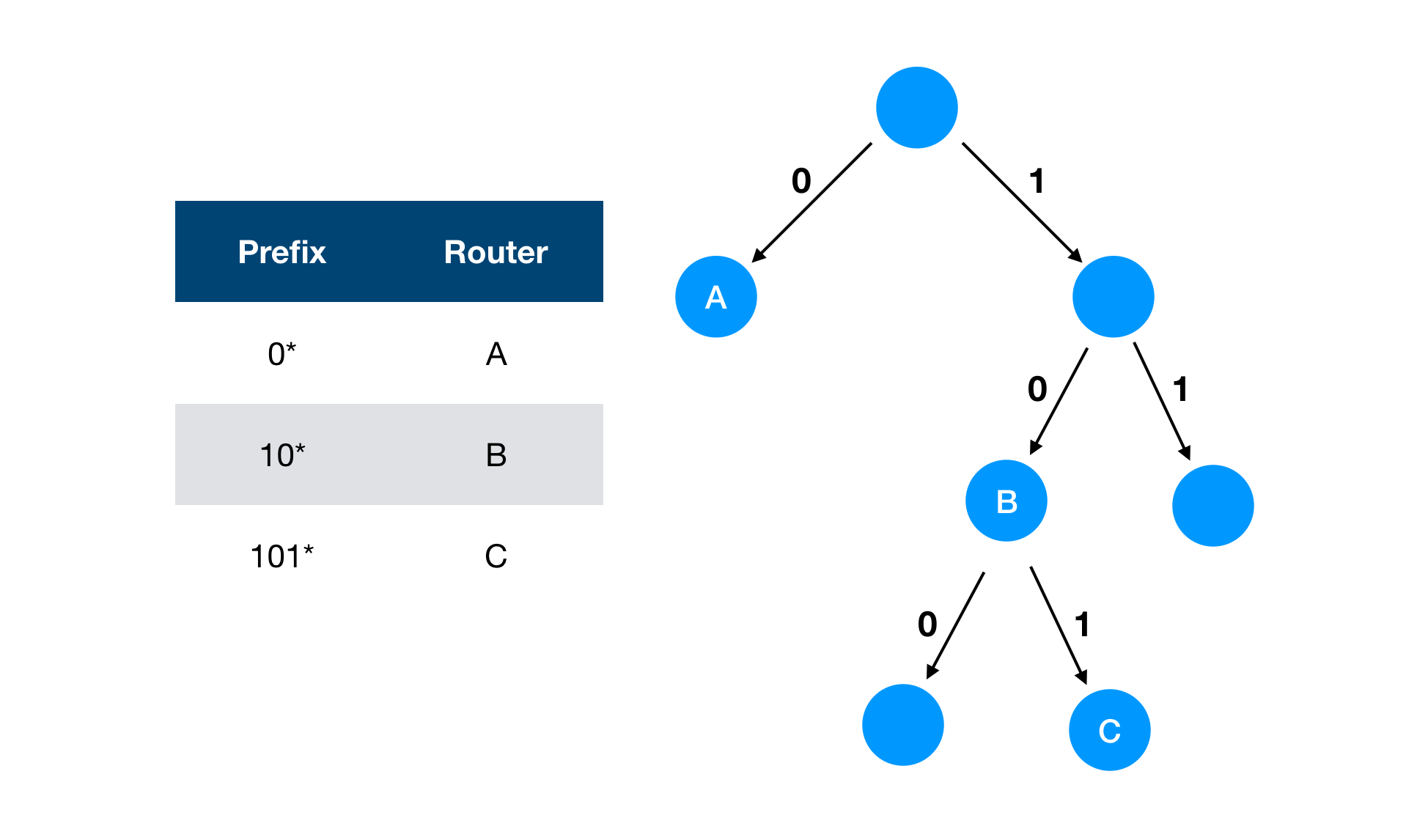
The left table represents the routing table. This routing table can be described as the right trie tree. Let’s say we have 1011 as input. It will be traversed as follows then find the node C as the next destination.
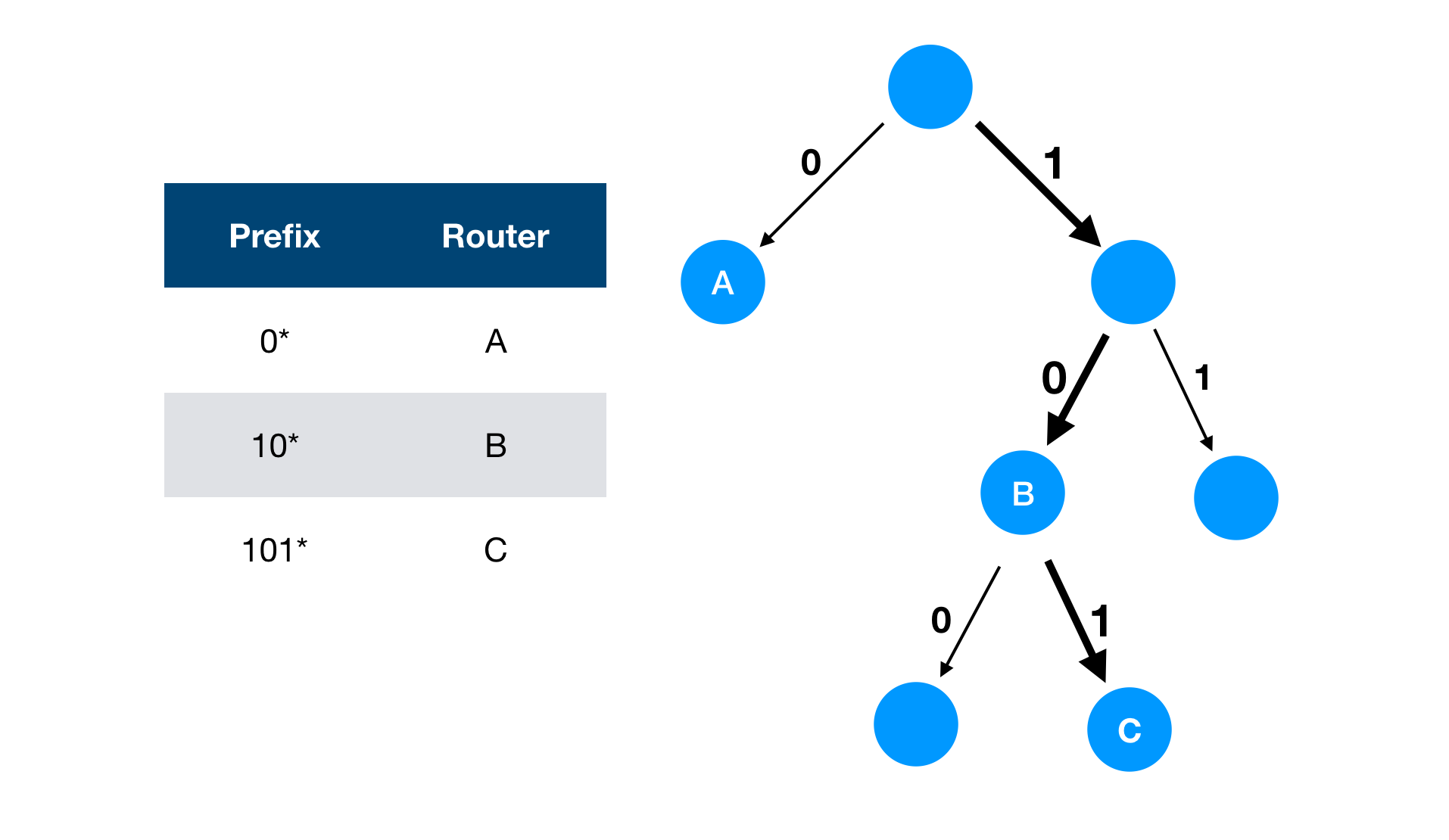
If 1000 comes, B will be picked up as the next destination because the node is the last node in the traversed route. Looking up the trie tree is very fast because the number of nodes to be visited is logarithm order.
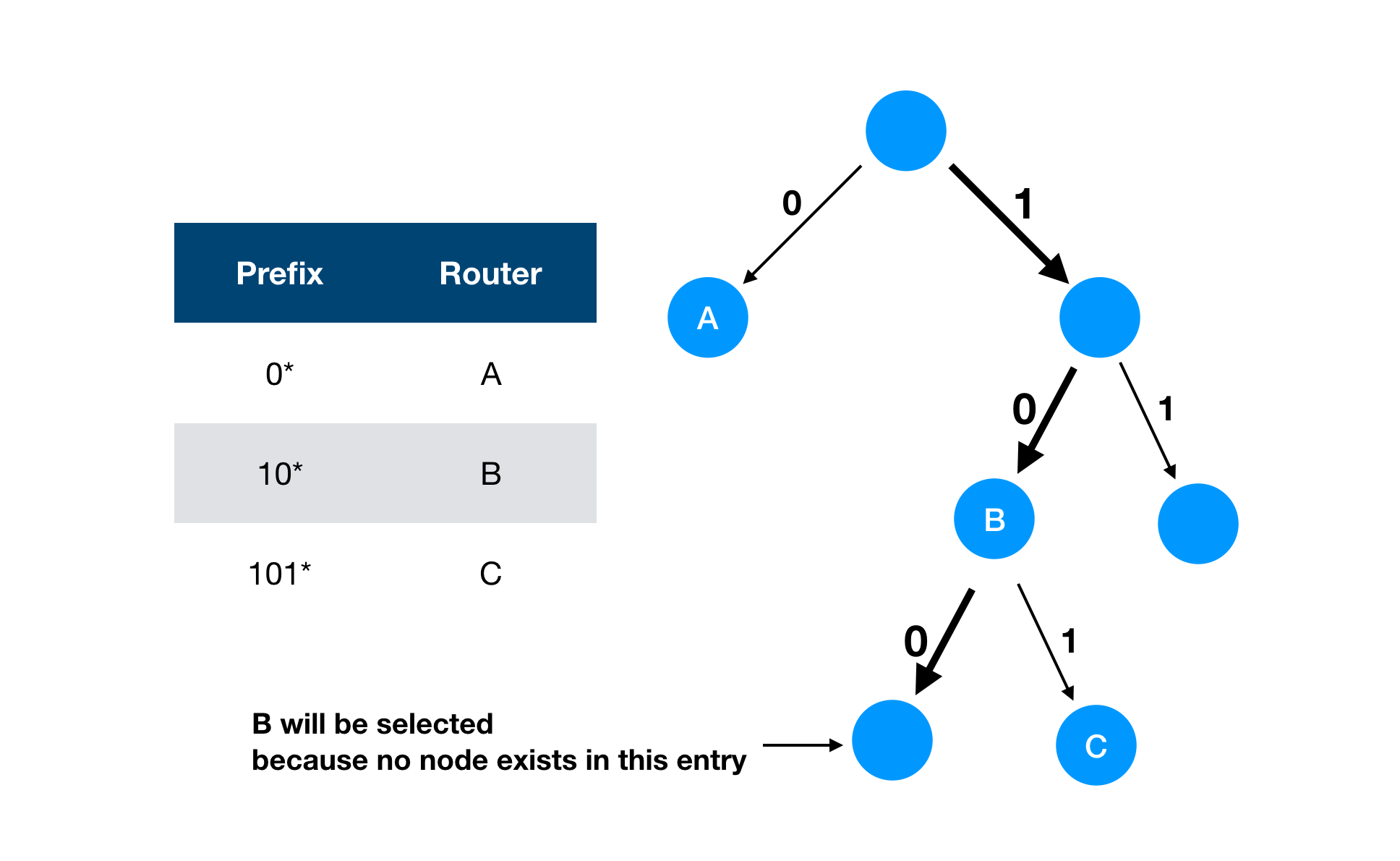
But using this kind of trie is still inefficient when it comes the number of memory access. It needs to visit up to 32 nodes for each IP address as IPv4 address has 32 bits. It grows more in case of IPv6. That is a huge overhead.
Direct Trie is an alternative to lookup efficiently with a reasonable amount of memory access. Multiple bits are represented by one node in a direct trie. By making a node representing several bits, we can reduce the depth of the tree so that looking up needs fewer memory accesses. This is a good resource to learn the direct trie in the longest prefix match. This video is also the reason why I described the algorithm because I’m learning CS6250 in OMSCS.
One drawback of the direct trie is that it consumes a significant amount of memory. As shown in the previous video, it creates 2^8 identical entries when it represents */16 prefixes because entries in the prefix */16 has the same prefix in the first 16 bits. It causes the first level with the same first 16 bits should have the same destination. That will be 2^8 (24 - 16 = 8). Although direct trie enables us to lookup efficiently, it is still a tradeoff problem.
Anyway, the trie is a common data structure used by looking up the longest prefix match IP address in routers on the Internet. If you want to learn the data structures including the comment tree structure, Introduction to Algorithms, 3rd Edition is the best book I’ve ever read.

I don’t think it’s an exaggeration to say it’s a bible to learn the algorithm and data structure. It may be an overkill for just learning the tree data structures but I believe it brings you a bunch of insight and fundamental pieces of knowledge about the algorithm and data structures every CS students should learn.
Thanks.