A few days ago, the second Presto Summit was held at the HQ of Facebook. This is the conference held by Facebook to gather developers and users of Presto around the world. There were a bunch of interesting talks and discussions related to Presto future. Recently, we have seen Presto Software Foundation forked the source code of Presto from the original repository maintained by Facebook. I had a little concern about the situation because it can be an obstacle to accelerate the development Presto and evolve the community. We have seen some discussion related to the problem too. Here is a report about the Presto Summit 2019.
Community
First, we could grasp the current community overview and the situation on Facebook
- 30 engineers in the core of Presto in Facebook
- 300 data warehouse team
- Facebook did not join Presto Software Foundation (PSF) but keep collaborating
- Used not only for interactive queries but also batch type workload
- There is no initiative about open source contribution. It’s up to each team
They are still welcoming the new features or advanced topics from the community. Although Facebook is not so interested in the enterprise features so much, they are likely to accept the patch if the community needs it. (e.g. security, new file format)
Basically, Facebook merges all commits both from internal and external into master so that all members in the community can receive the benefit immediately. Facebook considers them as the contributor in terms of scalability of the Presto. They validate the platform from the viewpoint of scalability by using the huge test suite and large test cluster. Since it’s a little difficult for the community to keep doing such kind of large scale test suites.
Facebook admits they did not actively keep updating the community in the past. They are going to change the policy and initiatives in the community in order to maintain the community active. Facebook has written documentation around the community guideline to achieve that. They are available in GitHub wiki.
- Presto Open Source Community Roles & Responsibilities
- How to Become a Presto Committer?
- Presto Development Guidelines
- Others
That wiki also includes several useful developer guides explaining the internal of Presto. So now Facebook seems to be engaging to contribute to the community and trying to make it much better.
Milestone
Here is the development plan happening in the near future in the Presto project.
Aria
Aria is a project to collect a number of performance-related experiments. One of them is to create a new memory layout for slice and pages used in Presto internally. People who are familiar with the Apache Arrow may easily grasp what it means. That would be able to reduce the memory pressure and CPU usage significantly. Another thing in Aria is an approach to make the push down better. It’s achieved by passing various kind of information to the connector side so that the splits created by the connector can do read skipping accordingly. There is also an interesting plan in Aria, vectorization. Supporting vectorization execution in Presto will make use of CPU resource more efficiently. Overall project Aria will pursue the potential to improve the basic performance of Presto further.

Presto Unlimited
Unlimited is another project to make the potential of Presto wider. It aims to remove the limitation of memory in each node by using materialized exchange join or aggregation operators. Since the join or aggregation are operators which consume a lot of memory and they tend to hit the local memory limit. Once an operator hits the memory limit, the whole query execution fails in Presto. In order to improve the reliability of query execution, partial recovery will be also introduced so that Presto can retry the part of the task instead of the whole query execution. Presto unlimited project will be able to eliminate the limitation in terms of memory and fault tolerance.

Coordinator Scalability
Coordinator currently does a lot of work, query analysis, planning, optimization, service discovery and worker management. Offloading some of these tasks can improve the scalability of the coordinator process. The scalability of coordinator will be much improved by this offload with high availability mechanism of Presto coordinator. Additionally, supporting various kind of transport encoding should be able to improve the scalability of the coordinator.

Others
Additionally, we can hear several interesting use cases of Presto in big tech companies.
- Twitter has multiple on-premise clusters with 200-500 notes
- Row-based permission is now on-going in Twitter
- Apache ranger support will come in the community
- Alibaba may be the biggest user of Presto who uses Presto as a backend of AnalyticDB of Alibaba cloud
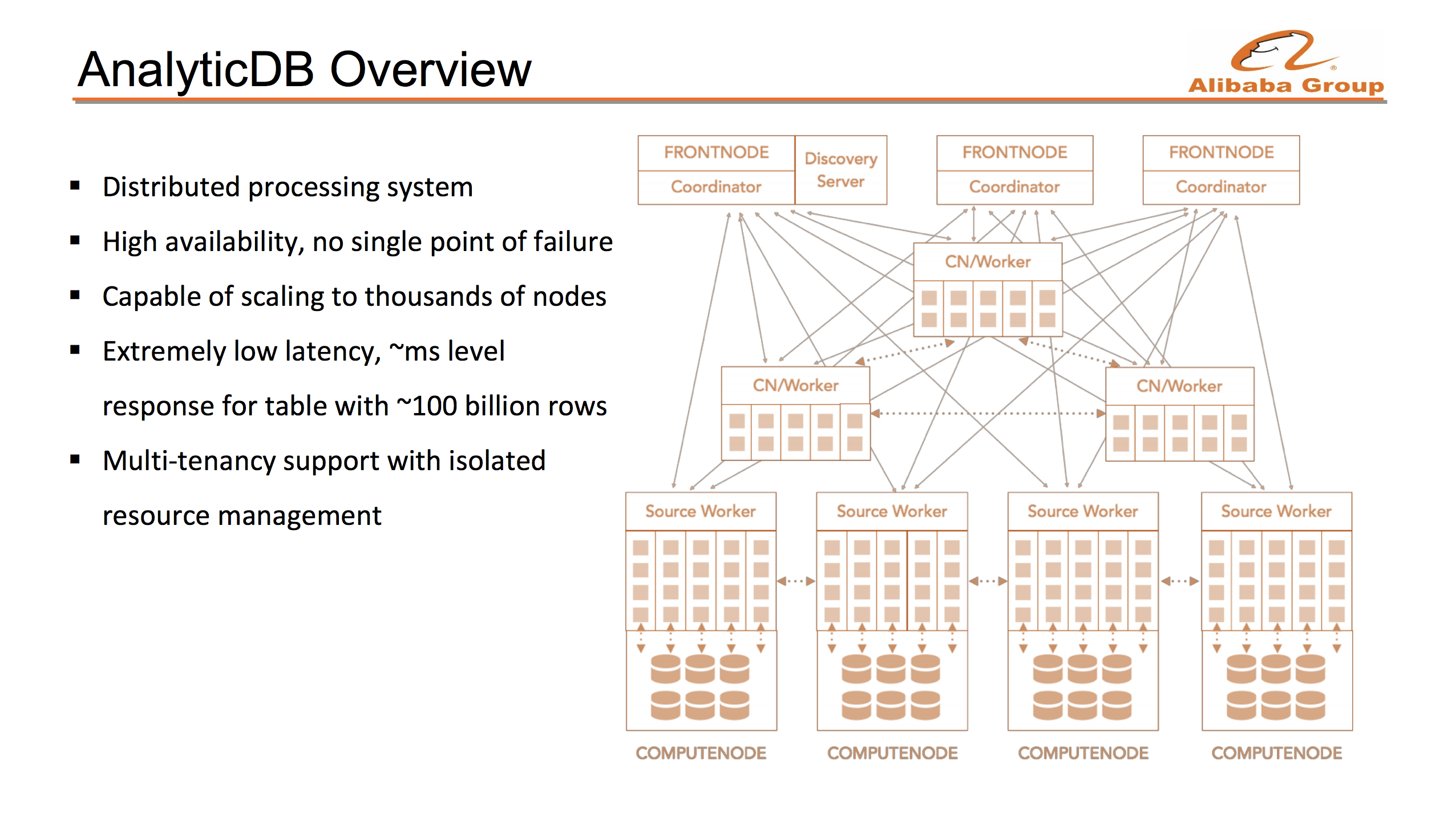
- 100K queries are running per second
- Supporting GPU operators make the speed 10 times faster
- Additionally, they already implement many advanced features (e.g. HA of coordinator, GPU operator, CBO) by themselves
- Uber has 2000 notes cluster running 160k queries per day
- They actively keep contributing to geospatial functions in Presto
- These functions are leveraged by the geo index optimization

- LinkedIn has its own query identification system to apply fine-grained optimization based on past history
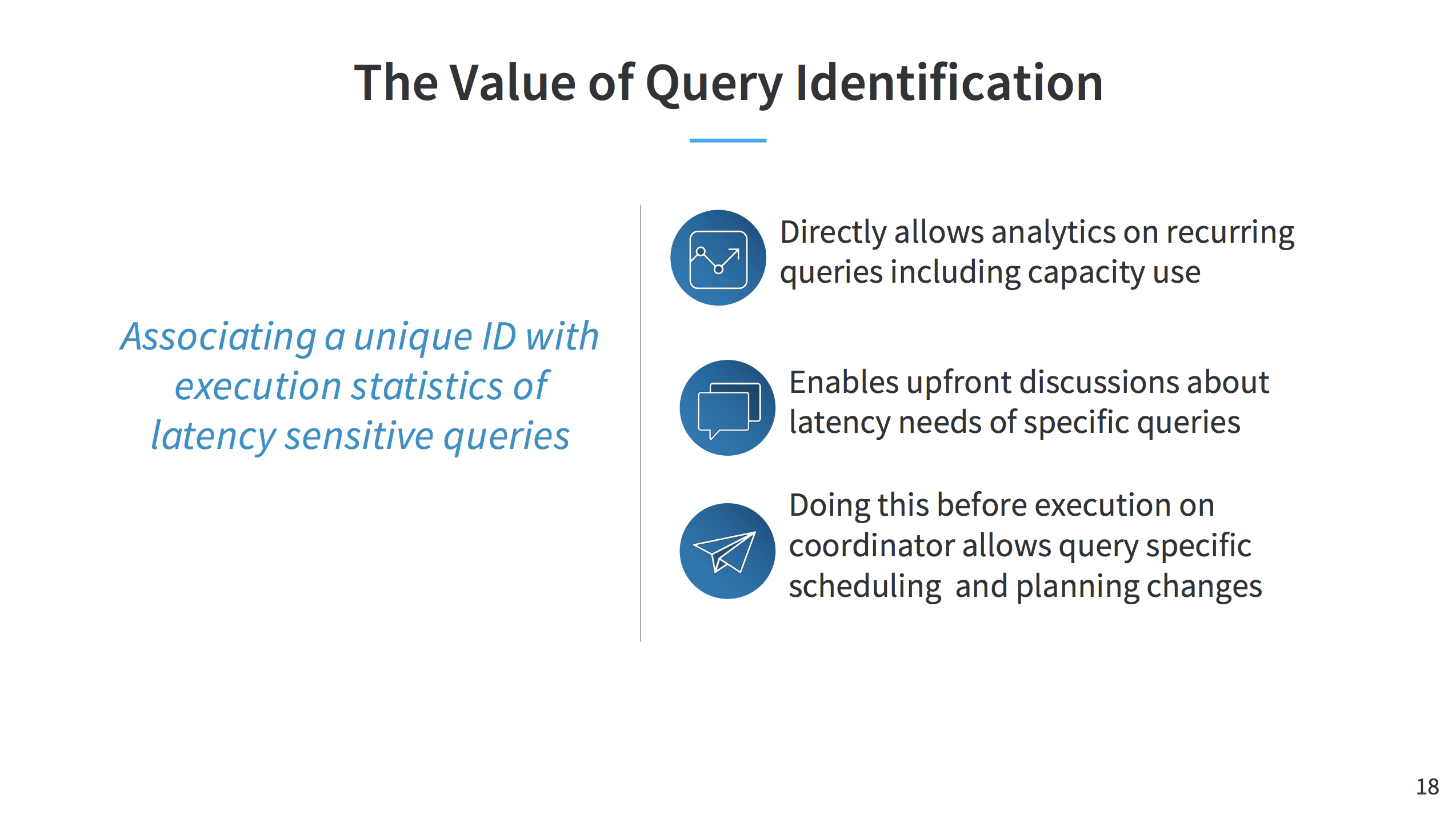
- It considers not only the query signature but also the properties of the query (e.g. filtering condition)
- That may also enable us to choose the specific cluster based on the category the given query belongs to
All slides are now available the wiki of GitHub. If you are not faimilar with Presto, “Learning Presto DB - Training DVD” will be a good resource to listen. Unfortunately, there is not so many books to learn about Presto. But it would be helpful to get started.

Thanks!